
Text-Driven Generative Framework for Multimodal Visual and Haptic Texture Synthesis
Authors: Myrah Naeem
Affiliation: Kyung Hee University, Haptics and Virtual Reality Lab
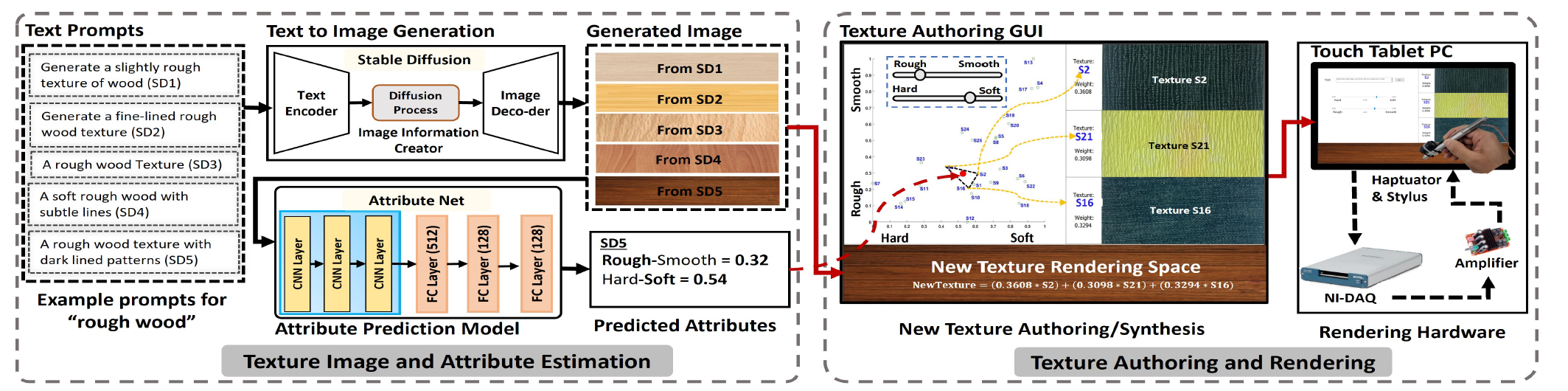
## Short Overview This work proposes a text-to-haptic generative framework that creates both visual textures and vibrotactile feedback directly from natural language descriptions. The pipeline combines a text-to-image model (Stable Diffusion), a regression-based perceptual predictor (AttributeNet), and an interpolation-based texture authoring algorithm to synthesize haptic signals aligned with the generated visual textures.
## Abstract This paper presents a novel framework for generating both visual and haptic textures from user-provided text descriptions. The proposed text-to-haptic pipeline combines generative AI with data-driven tactile rendering to enable intuitive and perceptually accurate texture synthesis. A text-to-image model (i.e., Stable Diffusion) generates high-quality visual representations of textures from descriptive text prompts. These visual textures are processed through a regression-based deep learning architecture, termed AttributeNet, which predicts perceptual attributes, such as roughness and softness, mapping them onto continuous perceptual scales. Finally, an interpolation-based texture authoring algorithm synthesizes vibrotactile signals based on the predicted attributes, enabling us to render haptic feedback aligned with the visual and textual input. To the best of our knowledge, this is the first complete framework to generate visual and haptic texture signals based on text-based inputs. AttributeNet’s haptic attribute predictions achieved improved accuracy over existing methods, and a user study further validated the framework, with participants favoring its quality and usability.